1. HPA简介
HPA全称HorizontalPodAutoscaler,即pod水平扩容,增加或减少pod的数量。相对于VPA而言,VPA是增加或减少单个pod的CPU或内存。HPA主要作用于Deployment或Statefulset的工作负载,无法作用于Daemonset的工作负载。
示例图:
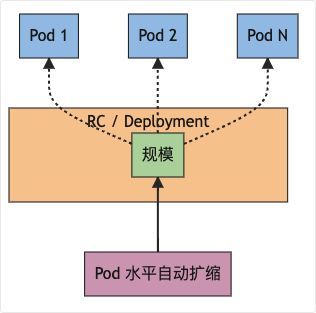
Kubernetes 将水平 Pod 自动扩缩实现为一个间歇运行的控制回路(它不是一个连续的过程)。间隔由 kube-controller-manager 的 --horizontal-pod-autoscaler-sync-period 参数设置(默认间隔为 15 秒)。
在每个时间段内,控制器管理器都会根据每个 HorizontalPodAutoscaler 定义中指定的指标查询资源利用率。 控制器管理器找到由 scaleTargetRef 定义的目标资源,然后根据目标资源的 .spec.selector 标签选择 Pod, 并从资源指标 API(针对每个 Pod 的资源指标)或自定义指标获取指标 API(适用于所有其他指标)。
HPA依赖metrics-server来获取CPU和内存数据,以下说明metrics-server的部署流程。
2. 部署metrics-server
下载metrics-server文件
1 | wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml |
修改启动参数,增加--kubelet-insecure-tls,否则会报获取接口证书失败。
1 | spec: |
创建yaml服务
1 | kubectl apply -f components.yaml |
通过kubectl top查看资源信息
1 | # kubectl top node |
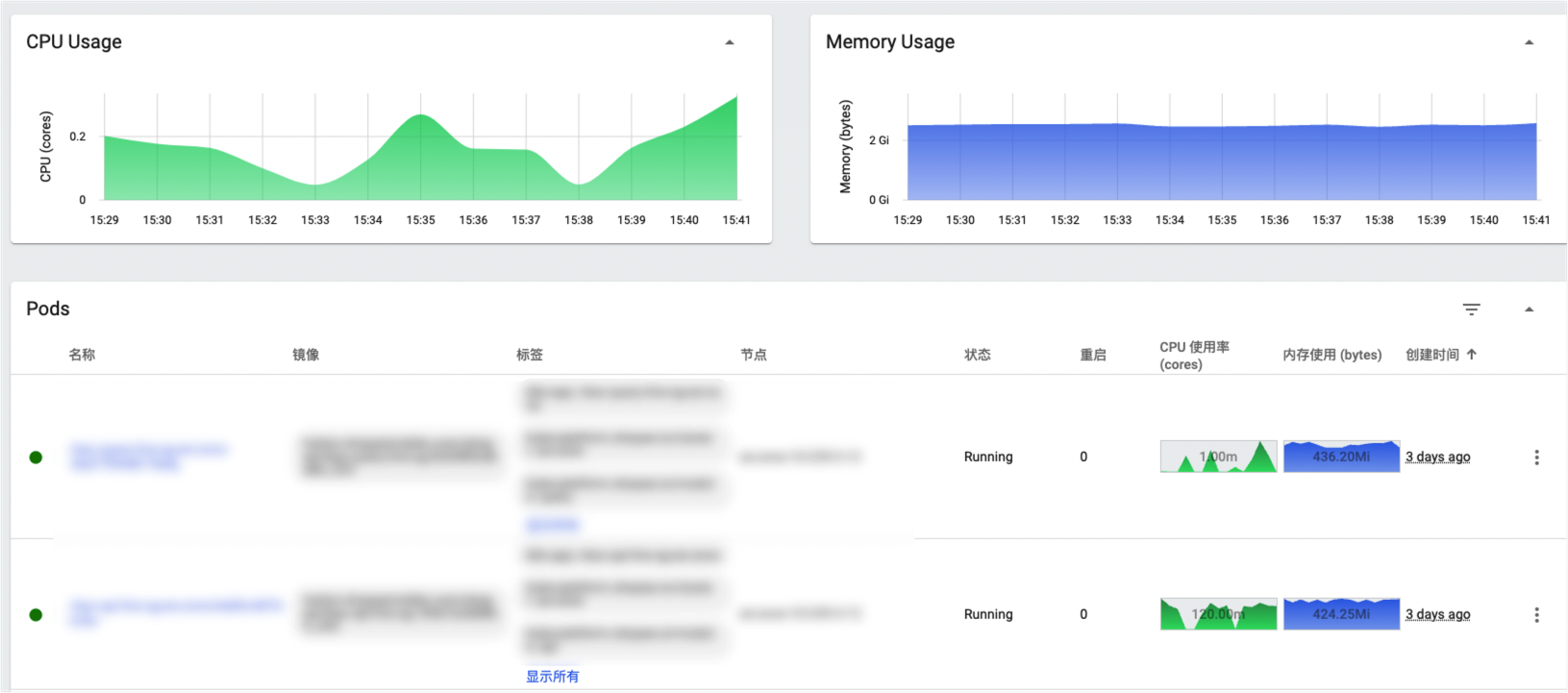
同时在k8s dashboard上也可以查看到实时的CPU和内存信息。
3. HPA配置
todo
参考:
- https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale/
- https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
- https://kubernetes.io/zh-cn/docs/tasks/debug/debug-cluster/resource-metrics-pipeline/#metrics-server
- https://github.com/kubernetes-sigs/metrics-server
- https://www.qikqiak.com/post/k8s-hpa-usage/
赏
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
支付宝打赏
微信打赏
赞赏一下